Как вы знаете, в VMware vSphere 5 версия файловой системы VMFS была продвинута до 5. Это дает множество преимуществ по сравнению с VMFS 3, в частности, возможность создания хранилищ виртуальных машин (Datastore) размером до 64 ТБ без необходимости создания экстентов.
Это стало возможным благодаря использованию GPT-разделов (GUID Partition Table) вместо MBR-разделов (Master Boot Record). При этом, существует ошибочное мнение, что для томов VMFS 3, обновляемых на VMFS 5, ограничения старой версии в 2 ТБ на файловую систему Datastore остаются. Это не так - VMFS 5.0 при обновлении на нее с третьей версии действительно сохраняет формат MBR, однако после расширения тома более 2 ТБ происходит автоматическая конвертация MBR в GPT-диск.
То есть, происходит это так. У нас есть том VMFS 3, мы нажимаем ссылку "Upgrade to VMFS 5":
После прохождения мастера обновления, видим что тип тома - VMFS 5:
Однако здесь также видно, что том VMFS (теперь уже 5-й версии) остался размеров в 2 ТБ, несмотря на то, что LUN может быть более 2 ТБ. Кроме того, том остался MBR-форматированным, а размеры блоков VMFS 3 для него остались неизменными (см. KB 1003565). Надо отметить, что вновь создаваемые тома VMFS 5 всегда создаются с унифицированным размером блока - 1 МБ.
Чтобы расширить том VMFS, вызываем мастер "Increase Datastore Capacity":
Расширяем том, например до 3 ТБ:
Обратите внимание, что VMFS 5 не дает нам увеличения размера файла (vmdk) по сравнению с предыдущей версией - максимум по прежнему 2 ТБ, просто теперь том может быть размером до 64 ТБ без экстентов.
Запустим fdisk, посмотрим свойства расширенного тома и увидим, что он теперь GPT-том:
Далее операции с таким диском производятся с помощью утилиты partedUtil, но это уже другая история.
Возвращаемся к проблеме тонких (thin) дисков VMware ESXi и уменьшения их размера после того, как они разрослись. Суть проблемы: когда вы используете тонкие диски для виртуальных машин - они постоянно растут, даже если вы удаляете в гостевой ОС. Это происходит потому, что ОС Windows (да и Linux) при удалении файлов не заполняет их блоки нулями, а просто помечает их удаленными в метаданных тома.
Deduplication - плагин для дедупликации хранилищ был переработан и теперь поддерживает журналирование данных. Также добавлена поддержка снапшотов для механизма дедупликации.
Новая версия плагина, обеспечивающего высокую доступность хранилищ (см. ниже).
В качестве отказоустойчивых хранилищ могут быть использованы файлы типа raw image.
iSCSI-трафик, идущий по каналу синхронизации между узлами StarWind HA теперь передается более быстро и надежно за счет замены транспорта MS iSCSI на собственный от StarWind (разработчики утверждают, что в MS iSCSI много багов, которые остались еще с 2006 года, что влияет на надежность решения).
Канал сигналов доступности (Heartbeat channel) теперь является обязательной конфигурацией для решения (во избежания несогласованности данных). Можно использовать для него публичную сеть - по нему не проходит много трафика.
Возможность "Switch partner" - для существующего узла StarWind HA может быть переназначен новый узел (помните, что требуется обновить пути доступа к хранилищам в ESX и Hyper-V).
Автоматическая синхронизация узлов после одновременного выключения двух узлов (например, отключение электричества). Если одно из дисковых устройств имеет более актуальные данные, то они будут автоматически синхронизированы на другой узел. Если вы используете методику кэширования write-back и хотя бы один из узлов был выключен некорректно (hard power off, например) - то автоматической синхронизации не произойдет, и будут ожидаться действия пользователя.
RAM disk - алгоритм генерации серийного номера был изменен для соблюдения его уникальности в пределах сети.
SPTI - параметр выравнивания буфера используется при проверки свойств устройства во время инициализации сервиса.
Скачать бета-версию StarWind Enterprise HA 5.8 можно по этой ссылке (без регистрации).
Таги: StarWind, Enterprise, Update, HA, Storage, iSCSI, VMware, Microsoft
Многие из вас знают продукт номер 1 для резервного копирования виртуальных машин VMware vSphere - Veeam Backup and Replication. Мы уже много писали как о функциональности Veeam Backup and Replication 5, так и о новых возможностях, которые появляются в Veeam Backup and Replication 6. В среду, 30 ноября, должен состояться релиз новой версии продукта, поэтому постараемся в этой статье собрать все новые функции, улучшения и нововведения Veeam Backup and Replication 6 (обратите также внимание на повышение цен на продукт с 1 декабря).
Приведенная ниже информация основана на документе "Veeam Backup & Replication. What's new in v6", который вы можете почитать в оригинале для понимания всех аспектов новых возможностей этого средства для резервного копирования виртуальных машин.
Новые ключевые возможности и улучшения Veeam Backup and Replication 6:
Enterprise scalability: улучшенная архитектура продукта позволяет производить развертывание в удаленных офисах и филиалах, а также для больших инсталляций. Теперь появилось несколько backup proxy серверов для крупных окружений (data movers), которые могут распределять между собой нагрузку в процессе резервного копирования, а управляет процессом сервер Veeam Enterprise Manager. Виртуальные машины динамически назначаются proxy-серверам с учетом алгоритма балансировки нагрузки, что снижает затраты на администрирование инфраструктуры РК. Также увеличена производительность для резервного копирования, репликации и восстановления по WAN-каналам.
Advanced replication: в некоторых случаях скорость репликации выросла до 10 раз, а также появится Failback (обратное восстановление виртуальной машины после возобновления работы отказавшего хоста с ВМ) с возможностью синхронизации дельты (различия данных с момента отказа основной машины на основном сервере и хранилище - Failover). Кроме того, поддерживается репликация в thin provisined-диски на целевой сервер. Это сильная заявка на победу над VMware SRM 5 (в издании Standard) для небольших компаний, где серверов не много и нужно укладываться в небольшие бюджеты. Появилась также возможность создания реплик базового образа для окружений VMware View.
Multi-hypervisor support: полная поддержка Windows Server с ролью Hyper-V и Microsoft Hyper-V Server, а также возможность управления резервным копированием для гипервизоров разных производителей из одной консоли. Одна и та же инсталляция Veeam Backup позволит делать резервные копии и с VMware vSphere, и с Microsoft Hyper-V. При этом лицензирование также единое - один пул лицензий Veeam вы можете распределить между лицензиями на процессоры для хостов ESXi и Hyper-V. Кроме того, появилась поддержка методики Changed Block Tracking для Hyper-V для ускорения процесса инкрементального резервного копирования (отслеживание изменившихся блоков с момента последнего бэкапа).
1-Click File Restore - с помощью 1-Click File Restore можно зайти в Enterprise Manager, выбрать нужный файл и восстановить туда, откуда он был удален (это можно сделать также из результатов поиска файла по резервным копиям). При этом есть разделение ролей - есть тот, кто может файл восстановить (helpdesk), а есть тот, кто открыть. Данная возможность доступна только в Enterprise Edition.
Полный список новых возможностей:
Архитектура Veeam Backup and Replication 6
ESXi-centric processing engine - теперь архитектура продукта полностью опирается на архитектуру ESXi, но в поддержка гипервизора ESX остается в полной мере.
Backup proxy servers - один сервер Veeam Backup может контролировать несколько прокси-серверов, обеспечивающих передачу данных на целевые хранилища. Прокси-серверы не нуждаются в Microsoft SQL
Server и содержат минимальный набор компонентов.
Backup repositories - новая концепция репозиториев резервного копирования (в традиционном РК известная как медиа-серверы), которые хранят настройки задач резервного копирования и параметры целевых хранилищ. Задачи по РК виртуальных машин с помощью медиа-серверов динамически назначаются proxy-серверам с учетом алогоритма балансировки нагрузки.
Windows smart target - в дополнение к Linux target agent, который помогает при резервном копировании в удаленные хранилища, появился также агент для Windows. Этот агент на целевой машине позволяет производить эффективную компрессию и обновлять синтетические резервные копии.
Enhanced vPower scalability - теперь можно использовать несколько серверов vPower NFS. Теперь можно запускать еще больше ВМ напрямую из резервных копий (например, если у вас много ВМ с большими дисками это очень может помочь). Любой сервер РК Veeam или Windows backup repository может быть таким сервером.
Ядро продукта Veeam Backup and Replication 6
Optimization of source data retrieval - теперь учитываются параметры дисковых хранилищ при обращении к виртуальным машинам. Это позволяет до 4-х раз увеличить производительность для одной операции, в зависимости от настроек дискового массива.
Reduced CPU usage - теперь в два раза меньше нагрузка задач на процессор, что позволяет запустить больше задач РК или репликации на одном сервере Veeam Backup или прокси-сервере.
Traffic throttling - теперь доступны опции по регулированию полосы пропускания, которые производятся на базе пары source/target IP. Эти правила могут быть основаны на времени операций - время дня или день недели.
Multiple TCP/IP connections per job - теперь агенты Data Movers могут инициировать соединение по нескольким IP-адресам, что существенно увеличивает скорость резервного копирования. Особенно это эффективно для репликации по WAN-каналам.
WAN optimizations - протокол передачи данных Veeam Backup был существенно доработан в плане производительности для передачи данных по соединениям с большими задержками в канале.
Exclusion of swap files - блоки, относящиеся к файлам подкачки, теперь исключаются из передачи в резервную копию, что существенно увеличивает производительность.
Enforceable processing window - теперь для каждой задачи можно задавать окно РК или репликации (все задачи, не попадающие в это окно завершаются). Также вне рамок окна не разрешается применение снэпшотов, что не позволяет оказывать влияние на производительность ВМ в рабочие часы.
Parallel backup and replication - теперь задачи, относящиеся к одной и той же ВМ, могут быть выполнены параллельно. Например, вы можете запускать ежедневную задачу Full Backup параллельно с работающей задачей репликации.
Улучшения резервного копирования в Veeam Backup and Replication 6
Backup mapping - при создании новой задачи резервного копирования ВМ, ее можно присоединить к уже имеющейся задаче (например, в ней есть уже файлы этой ВМ). В этом случае Full Backup этой ВМ может не потребоваться.
Enhanced backup file format - новый формат метаданных позволяет осуществлять быстрый импорт резервных копий, а также закладывает основу для поддержки новой функциональности в следующих релизах продукта.
Backup file data alignment - данные ВМ, сохраненные в бэкап-файле, могут быть размещены в пределах блоков по 4 КБ. Это увеличивает производительность дедупликации как самого Veeam Backup, так и сторонних технологий дедупликации (например, средствами дискового массива).
Improved compatibility with deduplicating storage - теперь механизм РК оказывает меньшее влияние на предыдущие файлы резервной копии, что улучшает производительность массивов, которые осуществляют пост-процессинг хранимых данных.
Репликация Veeam Backup and Replication 6
New replication architecture - теперь репликация использует двухагентную архитектуру, которая позволяет собирать данные хранилищ ВМ на исходном DR-сайте одним прокси-сервером РК и посылать их напрямую к прокси-серверу резервной площадки (и наоборот), минуя главный сервер Veeam Backup. Поэтому теперь не разницы, где размещать последний.
Replica state protection - теперь инкрементальные задачи репликации больше не обновляют последнюю точку восстановления ВМ. Это позволяет при прерывании задачи не перестраивать последнюю точку восстановления до того, как следующая задача откатит ее к последнему согласованному состоянию, как в прошлых версиях. В версии 6 последняя точка восстановления всегда согласована и ВМ может быть запущена в любой момент.
Traffic compression - за счет новой архитектуры репликации теперь не важно где находится основной сервер РК Veeam, а трафик сжимается намного более эффективно. Кроме того, появились настройки уровня компрессии для передаваемого трафика, что позволяет уменьшить требования к полосе пропускания до 5 раз.
Hot Add replication - теперь прокси-сервер на целевой площадке представляет диски реплики, используя технологию Hot Add. Это уменьшает поток трафика до 4 раз.
1-click automated failback - позволяет произвести обратное восстановление (Failback) виртуальной машины после возобновления работы отказавшего хоста с ВМ с возможностью синхронизации только дельты с момента последнего отказа (Failover), т.е. различия данных с момента отказа основной машины на основном сервере и хранилище) . Перед завершением этого процесса можно проверить ВМ на работоспособность на основной площадке.
1-click permanent failover - возможность в один клик провести все необходимые процедуры по завершению процесса превращения резервной машины в основную, когда в случае отказа основной ВМ она переместилась на резервный сайт.
Active rollbacks - репликация теперь хранит точки восстановления как обычные снапшоты ВМ. Это позволяет откатиться в любую точку на резервной площадке, даже без участия Veeam Backup.
Improved replica seeding - улучшения механизма организации репликации. Теперь репликация использует обычные бэкап-файлы, это позволяет уменьшить размер передаваемых данных, поддерживаются ВМ с тонкими (thin) дисками и многое другое.
Replica mapping - теперь реплицируемую виртуальную машину можно привязать к уже существующей ВМ на резервной площадке (например, ранее для нее использовалась репликация или на резервную площадку ее восстановили из резервной копии). Это позволяет не передавать весь объем данных для создания реплицируемой пары.
Re-IP - теперь можно задать правила автоматического назначения IP-адреса для восстанавливаемой ВМ. Это очень полезно, когда требуется восстановить ВМ на резервную площадку, где действует другая схема IP-адресации, в случае сбоя основной.
Cluster target - задачи репликации теперь поддерживают указание определенного хоста или кластера как целевого для репликации. Это позволяет убедиться в том, что при восстановлении ВМ она окажется доступной (например, на резервной площадке).
Full support for DVS - полная поддержка распределенных коммутаторов VMware Distributed Virtual Switches технологией репликации, что позволяет передавать состояние реплики без дополнительных ручных операций (например, в окружениях с VMware vCloud Director).
Automatic job update - операции failover и failback автоматически обновляют задачу репликации путем исключения из нее ВМ и повторного добавления.
Multi-select operations - в консоли теперь можно выбрать несколько ВМ для операций с репликацией. Например, при массовом выходе из строя хостов можно провести операции failover сразу с несколькими ВМ (аналогично и для failback).
Enhanced job configuration - теперь мастер создания реплицируемой пары поддерживает возможность настройки репликации на уровне vmdk-дисков, а также предоставляет возможность настроить целевые объекты: resource pool, VM folder и virtual network, где будет размещаться реплика и восстанавливаться ВМ.
Миграция виртуальных машин в Veeam Backup and Replication 6
Quick Migration - эта технология позволяет организовать миграцию виртуальной машины между хостами и/или хранилищами путем передачи данных ВМ в фоновом режиме (пока она запущена) и потом на время простоя (переключения) передается только дельта файлов vmdk. Переключение осуществляется с помощью технологии SmartSwitch или просто повторной загрузкой ВМ. По сути, эта функция - аналог vMotion и Storage vMotion, но с небольшим простоем ВМ.
SmartSwitch - эта технология позволяет передать текущее состояние ВМ от исходного хоста и хранилища к источнику на время переключения виртуальной машины между ними (с простоем). При этом процессоры исходного и целевого хостов должны быть совместимы по инструкциями.
Migration jobs - новый тип задач "миграция ВМ". С учетом имеющейся у вас лицензии на VMware vSphere, мастер миграции выполняет одну из следующих задач: VMware vMotion, VMware Storage vMotion, Veeam Quick Migration
with SmartSwitch или Veeam Quick Migration with cold switch. Это позволяет быстро перевести ВМ с хостов, для которых требуется срочное обслуживание или останов (например, электричество выключили, а они на UPS'ах) или перенести ВМ в другой датацентр с минимальным влиянием на доступность сервисов в ВМ.
Instant VM Recovery integration - задачи миграции ВМ теперь оптимизированы для работы с функцией Instant VM Recovery. Если задача миграции обнаруживает, что ВМ переносится из состояния, когда она была мгновенно восстановлена (т.е. дельта размещается на vPower NFS datastore), то постоянная составляющая этой ВМ берется из бэкап-файла, а различия уже с NFS-хранилища для ускорения процесса миграции и оптимизации производительности.
Копирование файлов в Veeam Backup and Replication 6
Support for copying individual file - поддержка копирования отдельных файлов. Задача по копированию файлов теперь поддерживается так же, как и для каталогов.
Восстановление виртуальных машин в Veeam Backup and Replication 6
1-click VM restore - при восстановлении ВМ в исходное размещение (самый частый случай), это может быть сделано в один клик.
Virtual Disk Restore wizard - новый режим восстановления позволяет восстановить отдельные vmdk-диски в их исходное размещение или присоединить к другой или новой ВМ. При этом мастер Virtual Disk Restore может восстанавливать диски как "thin" (т.е. растущими по мере наполнения данными), а также делает все необходимые настройки в заголовочном vmdk-файле.
Hot Add restores - Veeam Backup первым стал поддерживать технологию Hot Add не только для РК, но и для восстановления vmdk-дисков, что позволяет избежать проблем производительности.
Multi-VM restore - возможность восстановления сразу многих ВМ из графического интерфейса, что очень удобно для случаев массовых отказов хранилищ или хост-серверов.
Full support for DVS - полная поддержка распределенных коммутаторов VMware Distributed Virtual Switches и улучшения в интерфейсе по интеграции с ним (что удобно, например, при использовании совместно с vCloud Director).
Network mapping - при восстановлении виртуальных машин на сервер или площадку с другой конфигурацией виртуальных сетей, можно указать новые параметры сетевого взаимодействия.
moRef preservation - при восстановлении ВМ с заменой существующей копии, ее идентификатор сохраняется, что позволяет не перенастраивать задачи Veeam, а также стороннее ПО, работающее с виртуальными машинами по их идентификатору (почти все так и работают).
Восстановление на уровне файлов в Veeam Backup and Replication 6
Support for GPT and simple dynamic disks - теперь восстановление на уровне файлов поддерживает тома GPT и simple dynamic disks.
Preservation of NTFS permissions - опционально при восстановлении файлов Windows можно сохранить владельца и права на них в NTFS.
Индексирование и поиск файлов в резервных копиях Veeam Backup and Replication 6
Optional Search Server - теперь поиск по файлам гостевой ОС работает без Microsoft Search Server. Однако он рекомендуется для больших окружений с сотнями ВМ для лучшей производительности.
Reduced catalog size - размер каталога файловой системы гостевых ОС существенно уменьшился, что позволяет экономить место на сервере Veeam Backup.
User profile indexing - появилась поддержка индексации профиля пользователя в гостевой ОС.
Статистика и отчетность в Veeam Backup and Replication 6
Enhanced real-time statistics - теперь статистика в реальном времени по задачам РК улучшена в плане дизайна, чаще обновляется и более информативна для пользователя.
Improved job reports - отчеты о задачах РК лучше выглядят, имеют дополнительную информацию, включая количество изменившихся данных, уровень компрессии и коэффициент дедупликации.
Bottleneck monitor - в ответ на наиболее частые вопросы о низкой производительности в различных окружениях, Veeam сделала новый компонент, который позволяет выявить узкие места на различных стадиях РК и репликации. Все это отображается в статистике реального времени.
VM loss warning - история задач РК теперь оповещает пользователя о виртуальных машинах, которые раньше бэкапились, а потом задачи РК перестали существовать (например, случайно или намеренно удалили).
Интерфейс пользователя консоли Veeam Backup and Replication 6
Wizard improvements - все мастера были обновлены для возможности быстрой навигации при создании задач РК. Некоторые мастера стали динамическими - т.е. сфокусированными только на той задаче, которую вы хотите выполнить.
VM ordering - мастера резервного копирования и репликации теперь позволяют задать порядок, в котором ВМ должны обрабатываться.
Multi-user access - доступ нескольких пользователей к консоли теперь включен по умолчанию, позволяя нескольким пользователям получить доступ к консоли по RDP на одном сервере.
Веб-интерфейс Enterprise Manager в Veeam Backup and Replication 6
Job editing - в дополнение к управлению задачами, Enterprise Manager позволяет теперь менять их настройки для защищаемых ВМ, бэкап-репозитории, учетную запись гостевой ОС - все прямо из веб-интерфейса.
Job cloning - существующие задачи теперь могут быть клонированы прямо из веб-интерфейса с сохранением всех настроек.
Helpdesk FLR - появилась новая роль "File Restore Operator" в Enterprise Manager, которой делегированы полномочия по восстановлению отдельных файлов. Ее можно назначить персоналу службы help desk. При этом файлы восстанавливаются в их исходное размещение, а персоналу hepl desk можно ограничить возможности их скачивания, и, соответственно, доступа к ним (есть настройки касательно типов файлов и прочее).
FIPS compliance - веб-интерфейс теперь полностью совмести с стандартом FISP.
Design improvements - веб-интерфейс имеет множество улучшений в плане юзабилити и дизайна.
Улучшения технологии SureBackup в Veeam Backup and Replication 6
Improved DC handling - теперь улучшена работа с контроллерами домена в ситуациях, когда он оказывается изолированным в окружениях с несколькими DC.
Support for unmanaged VMware Tools - задачи SureBackup теперь поддерживают виртуальные машины с пакетами VMware Tools, которые установлены вручную.
Остальные улучшения Veeam Backup and Replication 6
Enhanced PowerShell support - расширены возможности PowerShell API, что позволяет управлять всеми настройками Veeam Backup. Все командлеты PowerShell были упрощены в плане синтаксиса (старый синтаксис также поддерживается). Появились маски в именах объектов, поиск объектов - все аналогично возможностям в консоли.
Log collection wizard - новый мастер, который собирает лог-файлы с защищенных хостов и подготавливает пакет, необходимый при обращении в техподдержку Veeam.
1-click automated upgrade - все компоненты продукта, включая те, что установлены на удаленной площадке (backup
proxy servers и backup repositories), могут быть просто обновлены с использованием мастера Upgrade wizard. При открытии консоли, Veeam Backup & Replication автоматически определяет компоненты решения, которые следует обновить.
Продукт Veeam Backup and Replication 6 должен быть доступен для скачивания с сайта Veeam ориентировочно в среду на странице загрузки продукта.
Несколько скриншотов. Восстановление файла резервной копии из результатов поиска в Enterprise Manager:
Настройки Traffic Throttling:
Мастер восстановления виртуальной машины Microsoftc Hyper-V:
Настройка бэкап-репозиториев:
Настройки Re-IP при восстановлении на резервной площадке:
Часто бывает, что от хоста ESX/ESXi нужно отвязать Datastore и LUN, на котором это виртуальное хранилище находится. При этом важно избежать ситуации All Paths Down (APD) - когда на хосте все еще остались пути к устройству, а самого устройства ему больше не презентовано. В этом случае хост ESX/ESXi будет периодически пытаться обратиться к устройству (команды чтения параметров диска) через демон hostd и восстановить пути.
В этом случае из-за APD хоста начнут возникать задержки других задач (поскольку таймауты большие), что может привести к различным негативным эффектам вплоть до отключения хоста от vCenter.
ESX/ESXi 4.1
В версии ESX/ESXi 4.1 демон hostd проверяет том VMFS на доступность прежде чем слать туда команды ввода-вывода (I/Os) Но это не помогает для тех I/O, которые находятся в процессе в то время, когда случилась ситуация APD.
Как описано в KB 1015084, правильно отвязывать LUN с хоста ESX/ESXi 4.1 так (все делается на каждом из хостов):
Разрегистрировать все объекты с этого Datastore (если они там есть), включая шаблоны - правой кнопкой по объекту, Remove from Inventory.
Убедиться, что этот datastore не используют сторонние программы.
Убедиться, что никакие из фичей vSphere для хранилищ (например, Storage I/O Control) больше не используются для этого устройства.
Замаскировать LUN на хосте ESX/ESXi, следуя инструкциям KB 1009449 через модуль PSA (Pluggable Storage Architecture).
Со стороны дискового массива распрезентовать LUN от хоста.
Сделать "Rescan for Datastores" на хосте ESX/ESXi.
Удалить правила маскирования LUN, которые вы сделали на шаге 4 по инструкции в KB1015084.
Убедиться, что не осталось путей к устройству, после того, как вы проделали все эти операции.
Для ESX/ESXi 4.1 процесс достаточно сложный, теперь давайте посмотрим, как это выглядит в ESXi 5.
ESXi 5.0
В ESXi 5.0 появился новый статус Permanent Device Loss (PDL), то есть когда хост считает, что дисковое устройство уже никогда не будет снова подключено, а ситуация APD рассматривается как временный сбой, после которого хост снова увидит пути и устройство.
Чтобы избавиться от сложной процедуры отключения LUN от хостов ESXi, VMware сделала операции detach и unmount в интерфейсе vSphere Client и в командном интерфейсе CLI.
Вот тут можно найти unmount Datastore (но устройство продолжит быть доступным):
А вот тут находится detach для самого устройства:
Как описано в KB 2004605, чтобы у вас не возникло ситуации APD, нужно всего-лишь сделать detach устройства от хоста. Это размонтирует VMFS-том (если там есть какие-нибудь объекты - vSphere Client вам сообщит об этом).
Таким образом правильная последовательность отключения LUN в ESXi 5.0 теперь такова:
Разрегистрировать все объекты с этого Datastore (если они там есть), включая шаблоны - правой кнопкой по объекту, Remove from Inventory.
Убедиться, что этот datastore не используют сторонние программы.
Убедиться, что никакие из фичей vSphere для хранилищ (например, Storage I/O Control или Storage DRS) больше не используются для этого устройства.
Сделать detach устройства на хосте ESXi, что также автоматически повлечет за собой операцию unmount.
Со стороны дискового массива распрезентовать LUN от хоста.
Сделать "Rescan for Datastores" на хосте ESXi.
Ну и в качестве дополнительного материала можно почитать вот эти статьи:
Как вы знаете есть самое лучшее средство для создания отказоустойчивых хранилищ iSCSI - StarWind Enterprise HA. С его помощью можно, используя всего 2 физических сервера, создать недорогое хранилище для виртуальных машин (в том числе на базе локальных дисков серверов) с поддержкой возможностей HA/vMotion/SVMotion и т.п., которое переживет отказ одного из узлов без простоя виртуальных машин. Кроме того, есть отдельная версия продукта для создания отказоустойчивого хранилища и кластера ВМ на базе всего двух серверов - StarWind Native SAN for Hyper-V.
Пользователи StarWind часто спрашивают, а как можно создать резервную копию конфигурации самого сервера StarWind? Ведь если у вас много хранилищ (например, вы их цепляете с дискового массива), то в случае переустановки Windows или сбоя сервера их восстановление может занять значительное время.
Выход прост и элегантен - нужно просто бэкапить/восстанавливать файл starwind.cfg и убедиться в том, что буквы дисков (где лежат ima-файлы хранилищ) остались теми самыми, что и раньше, после переустановки или восстановления ОС. Все это применимо и к StarWind Enterprise HA для обоих узлов HA. Таким же образом можно организовать и переезд одного из узлов StarWind на другой сервер.
Несмотря на то, что в VMware vSphere Client диски виртуальных машин создаются уже выровненными относительно блоков системы хранения данных, многих пользователей платформы беспокоит, не выглядит ли их дисковая подсистема для ВМ таким образом:
Специально для таких пользователей, на сайте nickapedia.com появилась бесплатная утилита UBERAlign, которая позволяет найти виртуальные диски машин с невыровненными блоками и выровнять их по любому смещению.
Но самое интересное, что утилита UBERAlign работает еще и как средство, позволяющее уменьшать размер виртуальных дисков ВМ с "тонкими" дисками (thin provisioning), возвращая дисковое пространство за счет удаленных, но не вычищенных блоков.
Скачать UBERAlign можно по этой ссылке (а вот тут в формате виртуального модуля OVA), полный список возможностей утилиты можно найти тут (там еще несколько видеодемонстраций).
Как мы уже писали, недавно компания StarWind выпустила решение StarWind Native SAN for Hyper-V (возможности см. тут), которое позволяет построить кластер отказоустойчивости серверов и хранилищ для виртуальных машин Hyper-V, используя всего лишь 2 физических сервера, что вдвое сокращает затраты на внедрение решения и его обслуживание.
10 ноября компания StarWind проводит вебинар по продукту Native SAN for Hyper-V, ведет его Анатолий Вильчинский, который, как не трудно догадаться, говорит по-русски, поэтому вы сможете задать все интересующие вас вопросы по решению для вашей виртуальной инфраструктуры Hyper-V.
Дана и время вебинара: 10 ноября в 19-00 по московскому времени.
Интересный момент обнаружился на блогах компании VMware. Оказывается, если вы используете в кластере VMware HA разные версии платформы VMware ESXi (например, 4.1 и 5.0), то при включенной технологии Storage DRS (выравнивание нагрузки на хранилища), вы можете повредить виртуальный диск вашей ВМ, что приведет к его полной утере.
In clusters where Storage vMotion is used extensively or where Storage DRS is enabled, VMware recommends that you do not deploy vSphere HA. vSphere HA might respond to a host failure by restarting a virtual machine on a host with an ESXi version different from the one on which the virtual machine was running before the failure. A problem can occur if, at the time of failure, the virtual machine was involved in a Storage vMotion action on an ESXi 5.0 host, and vSphere HA restarts the virtual machine on a host with a version prior to ESXi 5.0. While the virtual machine might power on, any subsequent attempts at snapshot operations could corrupt the vdisk state and leave the virtual machine unusable.
По русски это выглядит так:
Если вы широко используете Storage vMotion или у вас включен Storage DRS, то лучше не использовать кластер VMware HA. Так как при падении хост-сервера ESXi, HA может перезапустить его виртуальные машины на хостах ESXi с другой версией (а точнее, с версией ниже 5.0, например, 4.1). А в это время хост ESXi 5.0 начнет Storage vMotion, соответственно, во время накатывания последовательности различий vmdk (см. как работает Storage vMotion) машина возьмет и запустится - и это приведет к порче диска vmdk.
Надо отметить, что такая ситуация, когда у вас в кластере используется только ESXi 5.0 и выше - произойти не может. Для таких ситуаций HA и Storage vMotion полностью совместимы.
Компания StarWind, выпускающая продукт номер 1 для создания отказоустойчивых iSCSI-хранилищ для виртуализации StarWind Enterprise HA, на прошлой неделе выпустила новый продукт для создания кластера хранилищ виртуальных машин StarWind Native SAN for Microsoft Hyper-V (подробнее тут и тут). Отличительной особенностью продукта является то, что он позволяет орагнизовать отказоустойчивую конфигурацию серверов и хранилищ на базе всего лишь 2-х серверов Hyper-V, что в 2 раза сокращает затраты на оборудование (серверы, коммутаторы) и обслуживание решения.
Таги: StarWind, SAN, Hyper-V, iSCSI, Storage, HA, TCO, VMachines
Скоро нам придется участвовать в интереснейшем проекте - построение "растянутого" кластера VMware vSphere 5 на базе технологии и оборудования EMC VPLEX Metro с поддержкой возможностей VMware HA и vMotion для отказоустойчивости и распределения нагрузки между географически распределенными ЦОД.
Вообще говоря, решение EMC VPLEX весьма новое и анонсировано было только в прошлом году, но сейчас для нашего заказчика уже едут модули VPLEX Metro и мы будем строить active-active конфигурацию ЦОД (расстояние небольшое - где-то 3-5 км) для виртуальных машин.
Для начала EMC VPLEX - это решение для виртуализации сети хранения данных SAN, которое позволяет объединить ресурсы различных дисковых массивов различных производителей в единый логический пул на уровне датацентра. Это позволяет гибко подходить к распределению дискового пространства и осуществлять централизованный мониторинг и контроль дисковых ресурсов. Эта технология называется EMC VPLEX Local:
С физической точки зрения EMC VPLEX Local представляет собой набор VPLEX-директоров (кластер), работающих в режиме отказоустойчивости и балансировки нагрузки, которые представляют собой промежуточный слой между SAN предприятия и дисковыми массивами в рамках одного ЦОД:
В этом подходе есть очень много преимуществ (например, mirroring томов двух массивов на случай отказа одного из них), но мы на них останавливаться не будем, поскольку нам гораздо более интересна технология EMC VPLEX Metro, которая позволяет объединить дисковые ресурсы двух географически разделенных площадок в единый пул хранения (обоим площадкам виден один логический том), который обладает свойством катастрофоустойчивости (и внутри него на уровне HA - отказоустойчивости), поскольку данные физически хранятся и синхронизируются на обоих площадках. В плане VMware vSphere это выглядит так:
То есть для хост-серверов VMware ESXi, расположенных на двух площадках есть одно виртуальное хранилище (Datastore), т.е. тот самый Virtualized LUN, на котором они видят виртуальные машины, исполняющиеся на разных площадках (т.е. режим active-active - разные сервисы на разных площадках но на одном хранилище). Хосты ESXi видят VPLEX-директоры как таргеты, а сами VPLEX-директоры являются инициаторами по отношению к дисковым массивам.
Все это обеспечивается технологией EMC AccessAnywhere, которая позволяет работать хостам в режиме read/write на массивы обоих узлов, тома которых входят в общий пул виртуальных LUN.
Надо сказать, что технология EMC VPLEX Metro поддерживается на расстояниях между ЦОД в диапазоне до 100-150 км (и несколько более), где возникают задержки (latency) до 5 мс (это связано с тем, что RTT-время пакета в канале нужно умножить на два для FC-кадра, именно два пакета необходимо, чтобы донести операцию записи). Но и 150 км - это вовсе немало.
До появления VMware vSphere 5 существовали некоторые варианты конфигураций для инфраструктуры виртуализации с использованием общих томов обоих площадок (с поддержкой vMotion), но растянутые HA-кластеры не поддерживались.
С выходом vSphere 5 появилась технология vSphere Metro Storage Cluster (vMSC), поддерживаемая на сегодняшний день только для решения EMC VPLEX, но поддерживаемая полностью согласно HCL в плане технологий HA и vMotion:
Обратите внимание на компонент посередине - это виртуальная машина VPLEX Witness, которая представляет собой "свидетеля", наблюдающего за обоими площадками (сам он расположен на третьей площадке - то есть ни на одном из двух ЦОД, чтобы его не затронула авария ни на одном из ЦОД), который может отличить падения линка по сети SAN и LAN между ЦОД (экскаватор разрезал провода) от падения одного из ЦОД (например, попадание ракеты) за счет мониторинга площадок по IP-соединению. В зависимости от этих обстоятельств персонал организации может предпринять те или иные действия, либо они могут быть выполнены автоматически по определенным правилам.
Теперь если у нас выходит из строя основной сайт A, то механизм VMware HA перезагружает его ВМ на сайте B, обслуживая их ввод-вывод уже с этой площадки, где находится выжившая копия виртуального хранилища. То же самое у нас происходит и при массовом отказе хост-серверов ESXi на основной площадке (например, дематериализация блейд-корзины) - виртуальные машины перезапускаются на хостах растянутого кластера сайта B.
Абсолютно аналогична и ситуация с отказами на стороне сайта B, где тоже есть активные нагрузки - его машины передут на сайт A. Когда сайт восстановится (в обоих случаях с отказом и для A, и для B) - виртуальный том будет синхронизирован на обоих площадках (т.е. Failback полностью поддерживается). Все остальные возможные ситуации отказов рассмотрены тут.
Если откажет только сеть управления для хостов ESXi на одной площадке - то умный VMware HA оставит её виртуальные машины запущенными, поскольку есть механизм для обмена хартбитами через Datastore (см. тут).
Что касается VMware vMotion, DRS и Storage vMotion - они также поддерживаются при использовании решения EMC VPLEX Metro. Это позволяет переносить нагрузки виртуальных машин (как вычислительную, так и хранилище - vmdk-диски) между ЦОД без простоя сервисов. Это открывает возможности не только для катастрофоустойчивости, но и для таких стратегий, как follow the sun и follow the moon (но 100 км для них мало, специально для них сделана технология EMC VPLEX Geo - там уже 2000 км и 50 мс latency).
Самое интересное, что скоро приедет этот самый VPLEX на обе площадки (где уже есть DWDM-канал и единый SAN) - поэтому мы все будем реально настраивать, что, безусловно, круто. Так что ждите чего-нибудь про это дело интересного.
Таги: VMware, HA, Metro, EMC, Storage, vMotion, DRS, VPLEX
Мы уже много писали о новом продукте StarWind Native SAN for Hyper-V, который позволит создать кластер отказоустойчивости серверов и хранилищ для виртуальных машин Hyper-V, используя всего 2 хост-сервера (это намного дешевле традиционных решений).
Напоминаем, что продукт выходит завтра, 18 октября.
Вебинар: "StarWind Native SAN for Hyper-V: конвергенция гипервизора и СХД"
18 октября, вторник
StarWind Native SAN for Hyper-V работает на локальном Hyper-V сервере и обеспечивает высокую доступность СХД при минимальных затратах и простоте развёртывания. Продукт идеально подходит для представителей малого и среднего бизнеса, которые не могут позволить себе аппаратные СХД, но хотят использовать следующие преимущества Hyper-V кластера:
Высокая доступность
Защита от сбоя жесткого диска
Защита от единой точки отказа. Безшовная интеграция с Hyper-V
Одно из существенных изменений, Datastore Heartbeating - механизм, позволяющий мастер-серверу определять состояния хост-серверов VMware ESXi, изолированных от сети, но продолжающих работу с хранилищами. Напомним, что в качестве heartbeat-хранилищ выбираются два, и они могут быть определены пользователем. Выбираются они так: во-первых, они должны быть на разных массивах, а, во-вторых, они должны быть подключены ко всем хостам.
Если у вас доступно общее хранилище только одно, вы получите такое предупреждение в vSphere Client:
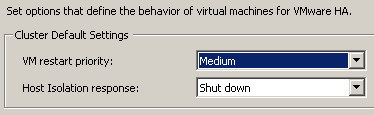
Теперь еще один момент, на который хочется обратить внимание. Помните, что в настройках VMware HA есть варианты выбора действия для хост-сервера по отношении к своим виртуальным машинам в том случае, когда он обнаруживает, что изолирован от сети (параметр Isolation Responce):
Напомним, что Isolation Responce может принимать следующие значения:
Leave powered on (по умолчанию в vSphere 5 - оптимально для большинства сценариев)
Power off
Shutdown
Выбирать правильную настройку нужно следующим образом:
Если наиболее вероятно что хост ESXi отвалится от общей сети, но сохранит коммуникацию с системой хранения, то лучше выставить Power off или Shutdown, чтобы он мог погасить виртуальную машину, а остальные хосты перезапустили бы его машину с общего хранилища после очистки локов на томе VMFS или NFS (вот кстати, что происходит при отваливании хранища).
Если вы думаете, что наиболее вероятно, что выйдет из строя сеть сигналов доступности (например, в ней нет избыточности), а сеть виртуальных машин будет функционировать правильно (там несколько адаптеров) - ставьте Leave powered on.
Разницу между Power off и Shutdown многие из вас знают - во втором случае машина выключается средствами гостевой системы, а в первом случае - это жесткое выключение средствами хост-сервера. Казалось бы, лучше всего ставить второй вариант (Shutdown). Но это не всегда так. Дело в том, что при действии shutdown у гостевой ОС может не получиться погасить систему (например, вылетит exception или еще что). В этом случае хост ESXi будет пытаться сделать shutdown в течение 5 минут до того, как он уже сделает действие power off.
Это приведет к тому, что время восстановления работоспособности сервиса вполне может увеличиться на 5 минут, что может быть критично для некоторых задач (с высокими требованиями к RTO). Зато в случае shutdown у вас произойдет корректное завершение работы сервера, а при power off могут не сохраниться данные, нарушиться консистентность и т.п. Выбирайте.
Мы уже рассматривали новые возможности платформы VMware vSphere 5, в состав которой входит продукт для резервного копирования виртуальных машин VMware Data Recovery 2.0 (vDR).
Остановимся на них несколько подробнее. Что появилось нового в vDR 2.0:
Виртуальный модуль Data Recovery использует 64-битную ОС CentOS 5.5, что улучшает масштабирование и надежность.
Swap-файлы (внутри гостевой ОС Windows и Linux) больше не включаются в резервные копии, что ускоряет процесс резервного копирования.
Операции Integrity check (проверка консистентности) и reclaim (высвобождение места) теперь можно запускать по расписанию (кроме того, работают быстрее). Кроме того, если процесс проверки будет приостановлен (например, вылезет за пределы окна обслуживания), то его можно продолжить с того же места, не запуская с начала. Кроме того, процесс может выполняться одновременно с другими задачами.
Улучшена устойчивость к нестабильности сетевого соединения.
Можно приостановить виртуальный модуль, чтобы новые задачи бэкапа не запускались.
Доступны оповещения администраторов по email об успешном и неудачном завершении задач.
Улучшенная производительность дедупликации.
Как мы видим, улучшения достаточно небольшие, поэтому vDR до продукта Veeam Backup and Replication еще далеко, шестая версия которого выйдет уже совсем скоро.
В первой части статьи мы уже рассматривали наиболее оптимальную конфигурацию средства VMware vSphere Storage Appliance для создания отказоустойчивого кластера хранилищ из трех хостов и описали, что происходит с хранилищами при отказе сети синхронизации (Back-End Network). Во второй части статьи мы расскажем о том, как конфигурация VSA отрабатывает отказ сети управления и экспорта NFS-хранилищ (Front-End).
Мы уже писали о новой версии платформы для виртуализации настольных ПК предприятия VMware View 5, которая имеет множество новых улучшений, позволяющих говорить о возможности внедрения решения в промышленных масштабах.
Как известно, при использовании виртуальных ПК существенно увеличивается риск утери или порчи данных пользовательской инфраструктуры, поскольку теперь десктопы централизованы в ЦОД и появляются различные SPOF-точки отказа (например, система хранения данных). Кроме того, возрастает риск утери десктопа вследствие неправильных кофигураций серверной инфраструктуры или дискового массива. В связи с этим важным оказывается вопрос резервного копирования виртуальных ПК, которому никто, почему-то, не уделяет значения. А вопрос действительно важный, и сложных моментов там хватает: конфигурация View Connection Server, View Composer, бэкапы связанных клонов и прочее.
Компания VMware выпустила очень нужный документ "VMware View Backup Best Practices", который рекомендуется почитать всем тем, кто планирует внедрение решения VMware View или его масштабирование из существующего пилота:
Сначала нам описывают инфраструктуру VMware View с точки зрения компонентов, которые нуждаются в резерировании:
Потом показывают структуру хранилищ:
Потом говорят о том, для каких компонентов необходимо производить резервное копирование.
Основные компоненты (помимо виртуальных машин):
View Connection Server
View Composer (если развернут)
vCenter server и хосты ESX/ESXi
Служба Active Directory
Если говорить о базах данных, то их вот сколько:
Хранилище View Connection Server AD-LDS
БД View Composer для событий (Events - если развернута)
БД vCenter server
Какие еще компоненты могут быть, которые нужно резервировать:
Репозиторий ThinApp, сконфигурированный на общей шаре
Хост View Transfer Server для офлайн-десктопов
База данных
View Error Log
В резервном копировании не нуждается Security Server (он не хранит изменяющихся данных), реплики View Connection Server и сторонние серверы управления VDI-инфраструктурой.
Резервное копирование виртуальных ПК на платформе vSphere. Производится аналогично бэкапу ВМ и конфигураций хостов для серверных нагрузок (лучше всего использовать Veeam Backup and Replication)
Резервное копирование хранилища View Connection Server AD-LDS
Бэкап базы данных View Composer
Бэкап базы vCenter
Для резервирования хранилища AD-LDS на Connection Server используется утилита vdmexport:
Этот файл ldf будет содержать конфигурацию LDAP для View.
Для базы данных View Composer можно использовать встроенные средства бэкапа SQL Server (сначала останавливаем службу View Composer Service).
Лучше если и Connection Server и Composer+vCenter будут в виртуальных машинах - тогда их проще будет восстанавливать вместе с базами (если они не внешние). Как бэкапить базу данных VMware vCenter должен знать любой администратор, обслуживающий vSphere как платформу.
Последовательность восстановления инфраструктуры View выглядит так:
Восстанавливаем базу vCenter
Восстанавливаем базу Composer (если база восстанавливается к по-новой установленному эксземпляру Composer, нужно прочитать
http://www.vmware.com/pdf/view45_admin_guide.pdf на странице 26 для настройки контейнера RSA-ключа)
Восстанавливаем хранилище View Connection Server AD-LDS на новой или старой инсталляции:
Stateful virtual desktops (данные сохраняются после выхода)
Stateless virtual desktop (данные не сохраняются после выхода)
Для связанных клонов все непросто - их можно бэкапить, например, с помощью Veeam Backup, однако восстанавливаются они только как индивидуальные десктопы. То есть их нужно сначала восстановить как ВМ на VMware vSphere, а потом назначить в VMware View как dedicated-десктоп.
Stateful-виртуальные ПК предлагается бэкапить и восстанавливать как обычные виртуальные ПК, а Stateless - в резервном копировании не нуждаются, поскольку там никаких критичных данные нет, такой десктоп может быть развернут по требованию из базового образа, а приложения в нем публикуются, например, с помощью ThinApp (но User Data-диск бэкапить необходимо, если он используется).
Также в документе приводятся основные рекомендации по частоте резервного копирования компонентов VMware View:
Вообще вся эта тема с резервным копированием виртуальных ПК VMware View кажется очень муторной. Пора бы уже какому-нибудь вендору выпустить специализированное решение для этой задачи. А как вы с ней справляетесь в своей инфраструктуре?
Мы уже писали о том, что такое виртуальный модуль VMware VSA, и как он работает в случае отключения сети синхронизации между хост-серверами VMware ESXi. Сегодня приведем несколько полезных материалов.
Во-первых, это документ "Performance of VSA in VMware Sphere 5", рассказывающий об основных аспектах производительности продукта. В нем приведен пример тестирования VSA на стенде с помощью различных инструментов.
Всем интересующимся производительностью VSA для различных типов локальных хранилищ и рабочих нагрузок в виртуальных машинах документ рекомендуется к прочтению.
Во-вторых, появилось интересное видео о том, как VMware VSA реагирует на отключение сети синхронизации хранилищ и сети управления VSA.
Отключение Front-end сети (управление виртуальным модулем и NFS-сервер):
Отключение Back-end сети (зеркалирование хранилищ, коммуникация в кластере):
Ну и, в-третьих, хочу напомнить, что до 15 декабря при покупке VMware vSphere 5 Essentials Plus + VSA вместе действует скидка 40% на модуль VSA.
Таги: VMware, VSA, Performance, Storage, vSphere, HA, SMB, Video
Как мы уже писали тут, тут и тут, компания StarWind, выпускающая продукт номер 1 для создания отказоустойчивых хранилищ iSCSI для виртуальной инфраструктуры, выходит на рынок с новым решением - StarWind Native SAN for Hyper-V.
Основная идея продукта - дать пользователям возможность строить кластер отказоустойчивости серверов и хранилищ на базе двух серверов Hyper-V вместо четырех. Это сократит издержки на покупку оборудования и обслуживание решения при увеличении производительности (рекомендуется использовать адаптеры 10G).
Интересно посмотреть на расчеты по экономической составляющей решения - затраты уменьшаются почти в два раза (не нужно покупать еще 2 сервера, использовать порты коммутаторов, меньше тратится электричества и проще обслуживание). У компании StarWind есть подробное описание статей затрат:
Расчеты выглядят вполне правдоподобно. Все это приводит к тому, что стоимость капитальных и эксплуатационных затрат на содержание одного приложения снижается на 20-30%.
Немного скорректировалась дата выхода продукта StarWind Native SAN for Hyper-V - он появится 18 октября (записаться на получение можно тут).
Таги: StarWind, iSCSI, Hyper-V, SAN, Storage, HA, Update, TCO
Мы уже писали о некоторых анонсах на VMworld 2011, одним из которых был проект по созданию облачного корпоративного хранения данных VMware Project Octopus. Это некий аналог сервиса Dropbox для хранения файлов, который позволит использовать его крупным предприятиям, поскольку в нем будут соблюдаться все необходимые политики безопасности (о дырках в Dropbox можно почитать тут,тут,тут), а также будут инструменты для организации рабочих процессов при работе с файлами. При этом, скорее всего, будет неплохой SLA по доступности.
Надо отметить, что Project Octopus можно будет использовать как из облака сервис-провайдера VMware, так и поставить у себя на серверах в виртуальных машинах, если данные в облако переносить боязно.
Помимо опубликованного нами видео, появился еще один небольшой рассказ о Project Octopus:
Интересно, что согласно исследованиям 80% хранимых файлов в компаниях не используются более двух лет, а значит их надо постепенно удалять на файловых хранилищах. У Octopus будет возможность нотификации пользователей о таких файлах, и если никто из владельцев не подтвердит их актуальность, они будут удалены. Также будут средства отката версий файлов, их сравнения, простое предоставление общего доступа коллегам и подписка на изменения файла.
Octopus предполагается интегрировать со следующими продуктами VMware: Zimbra Collaboration Server for Web-based applications (средства совместной работы), VMware View (использование общих данных в виртуальных ПК), VMware Horizon (управление данными приложений из корпоративного каталога) и AppBlast (доставка приложений через веб-браузер с поддержкой HTML 5 - то есть, открыл браузер - а там каталог приложений, выбираешь - и приложение открывается как будто установленное).
Кстати, вот пример работы Adobe Photoshop CSC в браузере средствами VMware Project AppBlast (на iPad, между прочим):
Естественно, для Octopus будут и клиенты для всех возможных типов устройств: ПК, планшетов, телефонов и смартфонов. И скоро для некоторых из записавшихся в бета-тестеры придут приглашения на этот интересный облачный сервис.
На самом деле, лично меня этот проект интересует больше всего, так как это действительно полезный и нужный сервис, который перетягивает инфраструктуру в облако с точки зрения данных (это проще), а не со стороны комплекса вычислительных ресурсов (IaaS).
С новыми инициативами и продуктами VMware, конечно, молодец. Но кое с чем не молодец вовсе. Например, с тем, что для России (помимо обнаглевшего повышения цен) с 1 октября отменяются преференции Emerging Markets, то есть становится ниже партнерская маржа и выше требования к партнерам. Типа все - рынок виртуализации развит, остальное - детали. При этом тут Hyper-V 3.0 набирает обороты, что все в совокупности приведет к тому, что SMB на VMware положит большой болт (VMware на SMB давно уже положила). Плохо, чо.
Мы уже писали о новом продукте "StarWind Native Storage Appliance for Hyper-V" для создания отказоустойчивого кластера хранилищ на базе всего двух серверов Hyper-V (то есть, там же запущены и виртуальные машины). 15 сентября Константин Введенский, сотрудник StarWind проводил по этому продукту вебинар на русском языке, рассказывая об основных особенностях решения (напомним, продукт выходит 15 октября).
Появилась запись этого вебинара, которую всем пользователям платформы виртуализации Microsoft Hyper-V просто необходимо посмотреть (нужно зарегистрироваться на сайте):
Мы уже писали о новых возможностях Hyper-V 3.0, которые появятся в готовящейся к выходу серверной платформе Windows Server 8, список которых позволяет говорить о серьезной конкуренции с платформой VMware vSphere в будущем.
Одна из таких интересных возможностей - это Live Storage Migration, которая позволяет перенести хранилище работающей виртуальной машины с сервера на сервер (при использовании локальных дисков) или между томами СХД (аналогом этой функции является Storage vMotion у VMware, которая доступна, начиная с издания vSphere Enterprise).
У Алексея Кибкало в блоге появился интересный обзор Live Storage Migration в Hyper-V 3.0 Developer Preview, в котором утверждаются, что данная функция (как и простой Live Migration) будет доступна бесплатно, в том числе в бесплатном издании Microsoft Hyper-V Server. При этом для работы Live Storage Migration и Live Migration не потребуется создавать кластеры.
Второй интересный момент - при миграции хранилища предоставляются гибкие возможности по переносу снапшотов. Можно перенести снапшоты, оставив оригинальный диск виртуальной машины на старом хранилище, можно перенести машину, оставив старые снапшоты, при этом все они останутся доступными для виртуальной машины:
Вообще, субъективно, Hyper-V 3 начинает мне нравится все больше и больше. Особенно на фоне офигевшей ценовой политики VMware в России. Понятно, что крупные компании с этой иглы уже не снимешь, а вот в среднем и малом бизнесе, похоже, назрели большие перемены в сфере виртуализации.
Таги: Microsoft, Hyper-V, Бесплатно, Storage, Live Migration, Blogs, SMB
Мы уже писали о новом продукте VMware vSphere Storage Appliance (VSA), который позволяет создать кластер хранилищ на базе трех серверов (3 хоста ESXi 5 или 2 хоста ESXi 5 + физ. хост vCenter), а также о его некоторых особенностях. Сегодня мы рассмотрим, как работает кластер VMware VSA, и как он реагирует на пропадание сети на хосте (например, поломка адаптеров) для сети синхронизации VSA (то есть та, где идет зеркалирование виртуальных хранилищ).
Таги: VMware, VSA, vSphere, Обучение, ESXi, Storage, HA, Network
На прошедшей конференции Build компания Microsoft раскрыла некоторые детали о новых возможностях своей обновленной платформы виртуализации на базе Hyper-V 3.0 в составе серверной ОС Windows Server 8.
В Hyper-V 3.0 появится множество интересных возможностей в сфере серверной виртуализации и VDI-инфраструктуры:
Поддержка до 160 логических процессоров на хостах Hyper-V
Поддержка до 2 ТБ RAM хост-сервера
Поддержка до 32 виртуальных процессоров виртуальных машин (vCPU) и до 512 ГБ оперативной памяти на одну ВМ
Поддержка технологии NUMA в гостевой ОС, что позволяет повысить производительность виртуальной машины
Поддержка нескольких одновременных "горячих" миграций (Live Migration)
Поддержка техники Storage Live Migration - миграция хранилища виртуальной машины без прерывания ее работы (это будет работать без необходимости наличия общего хранилища - на локальных дисках за счет встроенных возможностей репликации)
Новый формат виртуальных дисков VHDX, который позволяет создавать виртуальные диски объемом до 16 ТБ (вместо 2 ТБ в формате VHD). Также новый формат будет более производительным, надежным и поддерживать работу с большими блоками
Технология Offloaded Data Transfer (ODX), которая позволяет передать на сторону дискового массива операции по работе с хранилищами виртуальных машин (у VMware подобная технология называется vStorage API for Array Integration, VAAI)
Обновленный виртуальный коммутатор, предоставляющий расширенные возможности по виртуализации сетевого окружения виртуальной машин и возможности ее переносимости между облачными инфраструктурами (нечто похожее на технологию VXLAN от VMware и Cisco)
Поддержка виртуальных адаптеров (Virtual Fibre Channel) для виртуальных машин (до 4), через которые ВМ могут получить прямой доступ к LUN посредством Multi-Path I/O (MPIO). Также будут виртуальные Fibre Channel-коммутаторы
Поддержка загрузки хостов через Fiber channel и iSCSI SAN.
Поддержка технологии SR-IOW для привилегированного доступа к PCI-устройствам
Расширенные средства мониторинга производительности (CPU Metering и другое)
Пулы ресурсов для кластеров (Resource pools)
Поддержка дедупликации данных, позволяющей сократить тебуемое виртуальными машинами пространство на системе хранения, без существенной потери производительности. Это позволит также уменьшить окна резервного копирования
Прямая передача данных между хостами за счет Offloaded Data Transfer
Поддержка NIC Teaming и load balancing для создания виртуальных сетей на хосте (ранее это делалось с помощью сторонних драйверов)
Поддержка массивов JBOD и тонких дисков на JBOD (Thin Provision)
Поддержка средства Bitlocker для кластерных дисков
Новая версия файловой системы Cluster Shared Volume (CSV) 2.0 со встроенной поддержкой дедупликации и создания снапшотов со стороны массивов
Средство в GUI для управления IP-адресами (IPAM)
Поддержка CIFS/SMB-хранилищ с использованием протокола Remote Direct Memory Access (RDMA)
Технология Hyper-V Replica, позволяющая организовать асинхронную репликацию виртуальных машин (напомним, что в Veeam Backup and Replication 6 также будет такая возможность)
Поддержка технологии RemoteFX для RDP-сессии с хостом, улучшенная компрессия трафика для WAN-каналов
Возможность создания базового образа для виртуальных ПК (gold master image). Индивидуальные сессии пользователей могут быть настроены с помощью перемещаемых профилей (roaming profiles)
Поддержка до 63 хост-серверов и до 4000 виртуальных машин в кластере
Поддержка графических библиотек DirectX 10, OpenGL 1.1 и технологии Metro UI в виртуальных машинах
Службы Active Directory будут доработаны под виртуализацию (поддержка снапшотов ВМ, виртуализация контроллеров домена и их клонирование)
Встроенный брокер соединений с возможностью балансировки сессий
Возможность включения и отключения GUI сервера, превращая его в Server Core (и обратно)
Поддержка распределенного виртуального коммутатора Cisco NEXUS 1000V, который будет специально разработан под Windows Server 8
О Cisco NEXUS 1000V под Hyper-V можно почитать вот в этой статье.
Очевидно, что компания Microsoft сделала очень большой шаг на пути конкуренции с VMware vSphere, замахиваясь уже не только на сегмент среднего и малого бизнеса, но и на корпоративный сектор.
Windows Server 8 можно скачать как Developer Preview по этой ссылке.
Продолжаем рассказывать о решении номер 1 для создания отказоустойчивых кластеров серверов и хранилищ - StarWind Native SAN for Hyper-V. Напомню, что это решение позволит вам, используя всего 2 сервера и несколько сетевых адаптеров, создать надежное общее iSCSI-хранилище для виртуальных машин Hyper-V с поддержкой Live Migration и другой функциональности платформы виртуализации:
То есть и машины исполняются на этих серверах, и хранилища между ними синхронизированы и отказоустойчивы.
Суть такого сверхэкономного решения - это полный набор возможностей по созданию кластеров серверов и хранилищ (с полным спектром возможностей) без необходимости приобретения дополнительных коммутаторов и серверов под такую конфигурацию. По стоимости решения пока непонятно, но я думаю это будет вполне бюджетно.
В комментариях можете задавать свои вопросы - сотрудники StarWind на них обязательно ответят.
Кстати, StarWind Enterprise HA получил сертификацию "Works with Windows Server 2008 R2":
Не так давно мы писали о новом продукте "StarWind Native Storage Appliance for Hyper-V", который позволяет создать отказоустойчивый кластер хранилищ на базе всего двух серверов Hyper-V (то есть на обоих серверах и виртуальные машины, и узлы кластера StarWind).
Один из наших читателей обнаружил интересную особенность VMware VSA при установке в триальном режиме:
Скачивал триальную версию, ключ не дали, нигде. Но, ведь все продукты работают без каких-либо ключей 60 дней, и нигде не написано, что для VSA это не так, даже наоборот - при инсталляции пишется, что без ввода ключа должен установиться и работать в триальном режиме. Я склоняюсь, что VSA глючит... может, русскоязычный Windows не нравится.
Это действительно проблема - на форумах уже попадались точно такие же вопросы от других людей, пока без ответов.
Когда мы ставили VMware VSA, то просто ввели партнерский ключик, и все заработало. А у вас, читатели, такой проблемы нет? Все работает в триальном режиме? Отпишитесь, плз, если есть такая же проблема.
Еще один интересный момент о VSA. Мы уже писали, что есть конфигурации VSA с двумя и с тремя хостами VMware ESXi. В частности, вот пример реализации с двумя хостами:
Однако, суть здесь в том, что в этом случае VMware vCenter у вас должен быть физический, а не в виртуальной машине, поскольку по своей сути кластер трехузловой. Более подробно можно почитать об этом в KB 2004834 (Running vCenter Server in a virtual machine within a VSA cluster is not supported).
То есть нужен либо физический vCenter, либо хост ESXi, не входящий в состав VSA-кластера, c vCenter в виртуальной машине.
И последнее о VMware VSA. Если вы все-таки планируете покупку VMware vSphere Essentials Plus и продукта дополнения VSA, у компании VMware сейчас есть хорошее промо - эти два продукта вместе существенно дешевле, чем по отдельности (есть отдельная позиция в прайсе). Это получается даже чуть дешевле, чем покупать vSphere 4 + vCenter VSA Addon. Так что имейте в виду (а покупайте у нас).
1 миллион операций ввода-вывода в секунду на хост ESXi (этого в лаборатории добивались еще год назад при экспериментах в лабораториях VMware, тогда это держалось в секрете)
300 000 IOPS на одну виртуальную машину на хосте
Контроллеры Paravirtual SCSI (PVSCSI) эффективнее используют CPU, чем LSI Logic SAS
Ну и надо отметить, что задержки на одну операцию ввода-вывода меняются слабо с увеличением числа виртуальных машин.
Компания StarWind Software, выпускающая продукт StarWind Enterprise iSCSI - номер 1 на рынке для создания отказоустойчивых хранилищ для серверов VMware vSphere и Microsoft Hyper-V, продолжает развивать ветку продукта, относящуюся к платформе виртуализации Hyper-V.
Новый продукт StarWind Native SAN for Hyper-V, планируемый к выпуску 15 сентября 2011 года, представляет собой средство для создания отказоустойчивой двухузловой конфигурации хранилища iSCSI на базе двух серверов Hyper-V.
Суть нативности StarWind iSCSI SAN для Hyper-V в том, что для создания полноценного и отказоустойчивого хранилища для виртуальных машин вам не понадобится вообще больше никакого "железа", кроме этих двух серверов.
StarWind Native SAN for Hyper-V - это Windows-приложение, которое вполне может существовать на обычном Windows Server с ролью Hyper-V. Поэтому вам не нужно дополнительного бюджета, кроме денег на приобретение продукта, что весьма актуально для небольших организаций, где собственно и используется Hyper-V.
Таким образом, на базе двух серверов у вас получится кластер высокой доступности (HA) и отказоустойчивый кластер хранилищ. Это будет очень интересно.
Если вы будете на VMworld 2011, который будет на днях, вы можете подойти к стойке StarWind (под номером 661) - там будут русскоговорящие ребята, которые вам расскажут и о StarWind Native SAN for Hyper-V, и об обычном StarWind Enterprise HA для VMware vSphere (сейчас актуальна версия StarWind 5.7).
Ну а мы, в свою очередь, в скором времени поподробнее расскажем о том, как работает StarWind Native SAN for Hyper-V.
Таги: StarWind, Enterprise, SAN, Hyper-V, Storage, Hardware, HA
В новой версии платформы виртуализации VMware vSphere 5 появилась интересная возможность - Host Cache. Это механизм, который позволяет пользователю vSphere 5 выделить определенное место на локальных дисков хост-сервера ESXi (лучше всего, если это будут SSD-диски) для хранения свопируемых страниц памяти виртуальных машин. Это позволяет существенно увеличить скорость работы файлов подкачки виртуальных машин (vswp), так как они находятся на локальных высокопроизводительных дисках, и, соответственно, увеличить общее быстродействие инфраструктуры виртуализации.
Хорошая и развернутая статья о Swap to Host cache в VMware vSphere 5 есть у Duncan'а Epping'а, а здесь мы приведем основные ее выдержки.
Прежде всего, после установки VMware ESXi 5 хост может не увидеть локальные SSD-хранилища как пригодные для хранения кэша виртуальных машин. Для этого есть вот такой хак от Вильяма Лама. Далее мы идем на вкладку Configuration в vSphere Client и выбираем секцию Host Cache Configuration:
Тут мы можем задать объем дискового пространства на локальном томе VMFS, который мы можем использовать для файлов подкачки виртуальных машин, работающих на этом хосте. После включения этой возможности на этом локальном томе VMFS появится куча vswp-файлов, в которые гостевые ОС виртуальных машин этого хоста будут складывать свои свопируемые страницы памяти.
Поскольку эти своп-файлы находятся только на этом хосте, то при миграции vMotion содержимое страниц памяти из этих файлов надо скопировать на другой хост в его Host Cache или в vswp-файл в папке с виртуальной машиной на общем хранилище. Это, само собой, увеличивает время на миграцию vMotion, и это надо учитывать.
Что касается надежности при отказе хост-сервера, то тут нет проблем - так как при отказе хоста все равно его виртуальные машины перезапускаются на других хостах, то данные из файлов подкачки для ВМ уже не будут нужны.
Наблюдать за использованием Host Cache можно из VMware vCenter 5 с помощью метрик "Swap in from host cache" и "Swap out to host cache" (а также "rate..."). В результатах вывода консольной утилиты esxtop это метрики LLSWR/s и LLSWW/s.
Что будет когда место на локальном свопе Host Cache закончится? Сервер ESXi начнет копировать страницы в обычный vswp-файл, который находится в папке с виртуальной машиной, что само собой повлияет на производительность. Кстати, размер Host Cache можно изменять при работающем хосте и виртуальных машинах, поэтому лучше увеличивать его вовремя, да и в целом не доводить до большого свопа виртуальных машин (то есть, правильно сайзить хосты по памяти для ВМ). К примеру, Duncan рекомендует 128 ГБ SSD-диски в RAID-1 для 128 ГБ оперативной памяти хоста.
Альтернатива Host Cache - это задать параметр VM swapfile location для виртуальной машины в ее настройках, указав, например, локальный SATA или SSD-диск (можно использовать и быстрые общие хранилища).
Вы уже читали, что в VMware vSphere 5 механизм отказоустойчивости виртуальных машин VMware High Availability претерпел значительные изменения. Точнее, он не просто изменился - его полностью переписали с нуля. То есть переделали совсем, изменив логику работы, принцип действия и убрав многие из существующих ограничений. Давайте взглянем поподробнее, как теперь работает новый VMware HA с агентами Fault Domain Manager...
Таги: VMware, vSphere, HA, Update, ESXi, Storage, vCenter, FDM

 RSS
RSS